첫 번째 글에서는 거대언어모델(LLM; Lager Language Model)로 서비스(애플리케이션)를 구현하고자 할 때 알아야 할 필수적인 개념을 정리했습니다.
아래 링크에서 기본 개념 확인할 수 있어요.
거대언어모델(LLM)과 생성형 AI에 대한 모든 개념(feat. 챗GPT가 할 수 있는 일) (tistory.com)
거대언어모델(LLM)과 생성형 AI에 대한 모든 개념(feat. 챗GPT가 할 수 있는 일)
거대언어모델(LLM; Large Language Model)에 대해서 몇 차례 글을 쓸 겁니다. 이 연재 글을 통해서 누구나 자신의 업무 중 어디에다 AI를 적용할지 아이디어를 발굴할 수 있는 역량을 얻었으면 합니다.
mokeya2.tistory.com
이번 글에서는 거대언어모델을 우리 서비스 목적에 맞게 활용하기 위해 알아야 할 테크닉(Technique)을 소개합니다.
프롬프트 엔지니어링, 파인튜닝, 리트리버(Retrieval-augmented Generation), 하이퍼 파라미터 등 주옥 같은 개념들이 무더기로 나오니, 끝까지 잘 읽어 보시기 바랍니다.
LLM, 생성형 AI는 메타버스, 로봇 등 인접 분야에 정말이지 강력한 영향을 줄 거예요. IT 업계 있으면서도 이런 용어들 모르면 금세 도태되는 겁니다.

거대 언어모델 서비스 관련 기법(Technique)
언어모델은 사전에 학습된 언어 데이터를 기반으로 여러 가지 과업을 수행할 수 있습니다. 또한 학습량이 방대하기 때문에 주제, 분야를 가리지 않고 평균적인 수준의 산출물을 내어줄 수 있습니다. 즉, 국어, 영어, 수학, 사회, 과학 모두 곧잘 한다는 뜻인데, 이용자가 필요한 게 특정 영역에서의 특화된 지식, 과업이라면 큰 도움이 되지 않을 수 있습니다. 이 때는 몇 가지 기술/기법을 사용해 LLM이 이용자의 특수한 니즈에 맞는 정확한 산출물을 낼 수 있도록 조작해야 합니다.
프롬프트 엔지니어링(Prompt Engineering)
프롬프트 엔지니어링은 컴퓨터나 인공지능에게 정확하게 원하는 답변을 얻기 위해 질문이나 지시를 잘 만드는 기술입니다. 선배가 후배에게 업무 인수인계를 하듯이, 컴퓨터나 인공지능에게도 과업의 목적과 배경 등을 정확하고 명확하게 전달하는 것입니다. 이렇게 질문이나 지시를 잘 만드는 기술을 '프롬프트 엔지니어링'이라고 합니다.
기본적인 가이드라인 - G.S.T.A.R.를 포함해 작성할 것
- Goal(주제) : 대화의 중심이 되는 주제, 요구사항을 제시. “갑상선암 때문에 갑상선 절제 수술을 앞두고 의사 선생님께 물어볼 질문을 만들어줘 / 코드를 작성해줘 / 분석을 해줘 / 아이디어를 줘”
- Situation(상황) : 어떤 상황에서 내(이용자)가 질문을 하는지 / 챗GPT에게 기대하는 역할(Act as ~)은 무엇인지 / 어떤 채널(ex. 블로그, 업무 메일 등)에 사용할 정보인지, 타겟(ex. 암 환자나 보호자)은 누구인지 등
- Tone(양식) : 답변의 말투 / 서식(보고서, 표, 프로그래밍 코드, 프레임워크 등) / 문체의 난이도(ex. 중학생도 이해할 수 있게) 등
- Amount(분량) : 가령, 아이디어 5개 / 1분 길이의 대본(스크립트) / A4 용지 2장 분량 / 최대한 짧게 요약 등
- Remark(추가 고려) : 추가적으로 고려해야 할 사항. “OOO 관련 내용은 반드시 포함해 줘 / 네(챗GPT)가 필요한 정보가 있다면 질문해도 좋아” 등
샷(Shot)
- 제로샷(Zero Shot) : 응답 예시를 주지 않고 챗GPT가 가진 기본 능력으로 추론하여 답변하도록 하는 것
- 원샷(One Shot) : 한 개의 응답 예시를 제공하여 추론에 활용하도록 하는 기법
- 퓨샷(Few Shot) : 몇 가지(다섯 가지 이내) 답변 예시를 제공하고 이를 활용하여 답변을 생성하도록 하는 테크닉. 예시가 너무 많거나 일관되지 못 하면 오히려 답변에 방해가 되기도 함

CoT(Chain-of-Thought) : 원래는 답변에 도달하는 과정을 학습시킨 후에 질문을 하는 테크닉을 일컫지만, “단계별로 생각해 보자(Think step by step)”를 프롬프트에 추가하는 것만으로도 언어모델의 추론 능력이 향상됨.
우리가 초등학교 때 괄호가 포함된 산수 문제를 처음 배웠을 때처럼요. 12 * 25 ÷ {(2 + 5) * 2}
Generated Knowledge Prompting : 모델이 정확한 답변을 산출할 수 있도록 관련 지식이나 정보를 함께 제공하는 테크닉.


그 외 연구 중인 프롬프트 엔지니어링 기법
- Automatic Prompt Engineer(APE)
- Faithful Chain-of-Thought Reasoning
- Active-Prompt
- Directional Stimulus Prompting
- ReAct
- Multi-modal CoT Prompting
- Graph Prompting
프롬프트 사례를 아카이빙한 사이트
- 한국어 프롬프트 공유 커뮤니티 : 지피테이블 - 프롬프트/GPTs 공유 DB (gptable.net)
- OpenAI Cookbook : 프롬프트 테크닉을 모아둔 저장소 GitHub - openai/openai-cookbook: Examples and guides for using the OpenAI API
파인튜닝(Fine-tuning)
거대 언어모델을 특정 작업이나 데이터에 맞게 조정하는 과정입니다. 모든 학생이 다양한 과목을 배우지만 수학 시험을 볼 때는 수학에 더 집중하는 것과 비슷합니다. 파인튜닝(Fine-tuning)도 이처럼 모델이 일반적인 언어 이해에서 벗어나 특정 주제나 언어 스타일에 더 잘 맞도록 학습시키는 것입니다.
파인튜닝을 구성하는 핵심 요소
- 데이터 : 파인튜닝을 위한 데이터셋(Dataset)은 모델을 최적화시킬 특정 분야나 스타일의 예시들을 포함합니다. 예를 들어, 의료 분야에서 사용될 모델을 파인튜닝한다면 의료 관련 문서와 정보를 많이 포함한 데이터셋을 사용해야 할 겁니다.
- 학습 데이터는 prompt와 completion의 쌍으로 구성된 JSON Lines. 학습 데이터는 다다익선이며 최소 수백 개의 예제로 구성된 데이터를 권장
- 목적 : 모델을 어떤 목적으로 fine-tuning할지 결정해야 합니다. 이 목적은 문제 해결, 특정 언어 스타일 이해, 특정 주제에 대한 답변 제공 등 다양할 수 있습니다. 목적에 따라 사용되는 데이터와 훈련 방식이 달라질 수 있습니다.
- 파라미터 조정 : 모델의 파라미터(모델이 학습하는 내부 설정값)를 조정합니다. 이 과정에서 모델은 새로운 데이터에 맞게 자신을 조정하며, 이전에 배운 일반적인 언어 지식 위에 새로운 지식을 쌓아갑니다.
- <표> 모드(Mode)별 하이퍼 파라미터의 종류
| 모드 | 매개변수 | 설명 | 기본값 | 범위 |
| · 텍스트 생성(Complete) · 채팅(Chat) |
온도(Temperature) | 생성하는 텍스트의 무작위성을 조절하는 파라미터 · 수치가 클 수록 AI가 창의적인 답변을 출력 · 정답 내에서 답변하도록 하려면 작은 수치(0)을 부여 |
0.9 | 0~2 |
| · 텍스트 생성(Complete) · 채팅(Chat) |
최대 토큰 수(Maximum length) | 답변(Completion)의 최대 길이를 조절하는 파라미터 | 256 | |
| · 텍스트 생성(Complete) · 채팅(Chat) |
정지 문자열(Stop sequence) | 토큰 생성을 중단할 기준 문자열 · ex. 정지 문자열을 ‘.’로 지정하면 ‘.’가 출력된 시점에 출력이 중단 |
없음 | |
| · 텍스트 생성(Complete) · 채팅(Chat) |
Top P | 답변을 구성하는 토큰(단어)의 의외성을 조절하는 파라미터. 언어모델이 텍스트(답변)를 생성할 때 다음에 올 단어를 누적확률에 따라 선택하게 되는데, 이 확률의 임계치를 낮추면 제한된 풀(pool) 내에서 토큰을 선택하게 됨 · ex. 0.9이라고 설정하면 누적확률 상위 10%의 확률을 가진 토큰들 중에서 출력값을 선택. 아래 예시 참고 o “안녕” : 50% o “반가워” : 30% (누적 50+30=80%) o “고마워” : 15%(누적 50+30+15=95%. 이 시점에 임계치인 90%을 초과했기 때문에 멈춤) o 모델은 “안녕”과 “반가워” 두 단어 중에서만 선택 · 온도(Temperature)와 동시에 변경하지 말 것을 권장 |
1 | |
| · 텍스트 생성(Complete) · 채팅(Chat) |
빈도 페널티(Frequency penalty) | 동일한 텍스트를 출력할 가능성을 조절하는 파라미터 · 0에 가까울수록 자주 사용되는 단어나 구문의 반복 사용이 감소 |
0 | 0~2 |
| · 텍스트 생성(Complete) · 채팅(Chat) |
존재 페널티(Presence penalty) | 동일한 토큰의 반복 가능성을 감소시키는 파라미터 · 0에 가까울수록 아직 등장한 적 없는 새로운 단어나 구문의 사용이 감소 |
0 | 0~2 |
| 텍스트 생성(Complete) | Best of | 서버 측에서 {best_of}개의 결과를 생성하여 가장 좋은 결과를 반환 | 1 | |
| 텍스트 생성(Complete) | 시작 텍스트 삽입(Inject start text) | 답변(Completion) 앞에 항상 출력할 텍스트 | ||
| 텍스트 생성(Complete) | 재시작 텍스트 삽입(Inject restart text) | 답변(Completion) 뒤에 항상 출력할 텍스트 | ||
| 텍스트 생성(Complete) | 확률 표시(Show probabilities) | 토큰이 생성될 확률을 색상으로 구분하여 표현 · Off : 꺼짐 · Most likely : 가장 확률이 높은 것을 색상으로 구분 · Least likely : 가장 확률이 낮은 것을 색상으로 구분 · Full Spectrum : 양쪽을 두 가지 색으로 구분 |
||
| 이미지 생성 | n | 생성할 이미지 수 | 1 | 1~10 |
| size | 1024 X 1024 | · 256 X 256 · 512 X 512 · 1024 X 1024 |
||
| respose_format | 생성하는 이미지 형식(url / b64_json) | |||
| 음성-텍스트 변환 | 온도(Temperature) | 생성하는 텍스트의 무작위성을 조절하는 파라미터 · 수치가 클 수록 AI가 창의적인 답변을 출력 · 정답 내에서 답변하도록 하려면 작은 수치(0)을 부여 |
0.9 | 0~2 |
| prompt | 해당 파라미터를 통해 아래와 같이 지시할 수 있음 : · 모델의 스타일을 안내 · 모델이 잘못 인식하기 쉬운 특정 단어나 약어를 올바르게 텍스트화하도록 지시 · 분할되어 있지만 맥락은 동일한 파일들의 맥락을 유지하기 위하여 이전 파일의 트랜스크립트를 모델의 프롬프트로 제공. 이 경우 모델이 이전 음성의 맥락 및 정보를 활용하여 현재의 스크립트를 작성. 단 모델은 제공된 프롬프트의 마지막 224개 토큰만 고려하고 이전 것은 무시 · 스크립트의 구두점을 건너뛰지 않도록 지시 · 연결어(ex. “어…”, “Umm…” 등)를 스크립트에 남기고 싶을 때 이를 지시 |
|||
| response_format | 출력 파일 형식(json, text, srt, vervose_json, vtt) | json | ||
| language | 입력 음성의 언어(‘en’, ‘ko’ 등). 이를 추가하지 않아도 자동으로 언어를 탐지하지만 지정할 경우 처리 시간 단축 |
파인튜닝의 장단점
| 장점 | 단점 |
| - Fine-tuning - OpenAI API - 성공적으로 완료하면 프롬프트에서 맥락을 설명하기 위한 예시를 제공할 필요가 없어 토큰 수가 절약되고 요청 시 지연도 적어짐 - 가령, NCCN guidelines을 학습시키고 정답 내에서만 답변하도록 파인튜닝한 모델을 사용한다면, 그 이전처럼 매번 모델에게 “according to the NCCN guidelines ….”를 프롬프트에 입력할 필요가 없게 됨 |
- 목적에 맞는 데이터셋을 확보해야 함 - 확보한 데이터셋을 잘 전처리해야 함 - 데이터 확보, 전처리와 파인튜닝 자체에 상당한 비용이 투입될 수 있음 - 잘못된 데이터나 목표로 파인튜닝하면 모델이 편향되거나, 원치 않는 결과를 내놓을 수도 있음 |
참고. 2024년 1월 기준. 파인튜닝 가능한 OpenAI의 모델과 요금 - Pricing (openai.com)
| 계열 | 모델 | 설명 | Input | Output | Output usage |
| Fine-tuning models | - gpt-3.5-turbo - gpt-3.5-turbo-1106 (recommended) - gpt-3.5-turbo-0613 |
모델을 미세 조정하면 해당 모델에 대한 요청에 사용한 토큰에 대해서만 요금이 청구됩니다. | $0.0080 / 1K tokens | $0.0030 / 1K tokens | $0.0060 / 1K tokens |
| davinci-002 | - 모델을 미세 조정하면 해당 모델에 대한 요청에 사용한 토큰에 대해서만 요금이 청구됩니다. - Instruction을 추종하는 데에 최적화되어 있지 않고 성능이 떨어지지만 협소한 과업에 맞게 미세 조정하면 효과적으로 사용할 수 있습니다. |
$0.0060 / 1K tokens | $0.0120 / 1K tokens | $0.0120 / 1K tokens | |
| babbage-002 | $0.0004 / 1K tokens | $0.0016 / 1K tokens | $0.0016 / 1K tokens | ||
| gpt-4-0613 (experimental — eligible users will be presented with an option to request access in the fine-tuning UI) when creating a new fine-tuning job | |||||
과업 특화된 외부 모듈(DB, 기능)을 동원해 목적을 달성하는 LLM
이용자의 특정한 요청에 더 정확하고 적절하게 대응하기 위해, 언어모델은 ‘사전에 학습한 데이터’에만 기반해 답변을 제공하는 것이 아니라 외부 데이터(특정 영역, 혹은 특정 조직의 독자적인 데이터)나 외부의 기능(API)까지 동원할 수 있습니다.


지식 검색(Retrieval)
자신이 학습한(pre-trained) 것만으로 대화하던 언어모델이 외부의 지식(데이터)을 활용해 답변을 할 수 있도록 하는 것입니다.
Plus 플랜을 사용하고 계시다면, GPTs 메뉴에서 특정 데이터를 참조(Retrieval)해 답변을 생성하는 봇을 만들어보실 수 있습니다. 제가 실제로 만들었던 봇의 예시를 알려드릴게요.
GPTs로 콘텐츠에 태깅해주는 봇 만들기. 이 때 태그는 정해진 키워드 풀(Pool) 안에서 선택
- Description : 암에 대한 의학 정보 게시물을 읽고, 해당 게시물에 가장 적절한 태그(Tag)를 추천해 줍니다.
- Instruction :
- 봇의 목적 : 사용자는 의학 정보가 포함된 글을 프롬프트에 입력할 것이다. Content Tagger 봇은 프롬프트에 대해 사전에 정의된 키워드 목록("Knowledge"에 업로드된 키워드 목록 파일)에서 가장 관련성 높은 태그를 추천한다.
- 입력: 사용자로부터 입력받은 프롬프트. 주로 건강 정보, 의학 정보에 대한 글이 될 것이다.
- 처리: 프롬프트를 분석하여 주요 개념을 파악하고, 사전에 정의된 키워드 목록과 매칭하여 가장 적합한 키워드를 최대 10개 결정한다.
- 출력: 선택된 키워드 태그를 사용자에게 제시한다. 한국어로 답변하되, 프롬프트에서 영어로 표현한 단어는 답변에서도 그대로 영어로 표기한다. 이 때 답변 형식은, "{키워드 목록에 있는 키워드 중 이용자가 프롬프트에 입력한 의학 정보 글과 연관이 높은 키워드} : {키워드 목록 안에 존재하는지 여부 & 추천하는 이유}".
- 하이퍼파라미터 Temperature: 0
- Knowledge : 태그로 사용할 키워드의 목록(엑셀 ㅍ일)
Dialogue Manager / Agent / Assistant
요새 챗GPT나 네이버 CUE, 구글 Bard 같은 봇에게 일을 시켜보면, 이용자가 요청한 과업을 정확하게 수행하기 위하여 "이 콘텐츠에 적절한 키워드 태그를 추천해줘"라는 과업(Task)을 (봇이 알아서) 몇 가지 하위 과업(Sub-task)으로 나누어 수행했습니다.
이처럼 챗GPT를 비롯한 고도화된 생성형AI 챗봇 서비스에는 이용자의 요청에 따라 어떤 도구를 어떤 순서로 실행할 것인지 결정하는 모듈이 내재돼 있습니다.

- 인공 일반 지능(AGI; Artificial General Intelligence)에 가까울수록 여러 언어모델 중 가장 적합한 답을 해줄 수 있는 모델을 선별하고, 1개가 아닌 여러 모델의 답을 받아서 이를 조합하는 프로세스를 수행(MoE; Mixture of Expert) ← 이 조율을 Dialogue Manager / Agent(이후 ‘에이전트'라고 지칭)가 수행
- ex. 챗GPT는 16개의 LLM을 조합해서 답변 생산에 활용
- 에이전트가 작동하는 원리를 설명한 도식 - What is Auto-GPT, and why does it matter? (cryptonews.net)

- 과업을 정확히 수행하기 위해 에이전트는 앞서 설명한 지식 검색(Retrieval)을 비롯해 아래 여러 도구들을 동원합니다 :
- 메모리(Memory) : 에이전트의 과거 기억을 보관하는 모듈. 메모리를 사용하여 에이전트의 과거 대화 내용을 기억하고 그 정보를 현재 대화의 맥락으로 사용합니다.
- 추론(Reasoning) : 이용자의 질문에 답을 하기 위해 필요한 하위 과업과 질문을 추가로 생성해 작은 미션을 수행해 가며 최적의 답을 찾아가는 기능
- 1단계 : 다단계 추론(Multi-step Reasoning)을 통해 도구들을 어떻게 사용하여 목적을 달성할 수 있을지 계획
- 2단계 : 네이버 서비스들을 도구로 사용하면서 수립된 검색 계획을 수행(Tool Usage)

3단계 : 검색된 결과를 바탕으로 답변 생성(Retrieval-Augmented Generation)

- 기능 호출(Function calling) : 언어모델이 외부의 기능(API, 함수 등)을 활용하여 답변을 하는 것입니다. 단순히 정보만 제공하는 것에서 벗어나 예매, 구매, 결제까지 실행. 즉, 이용자의 의도에 맞는 ‘전환(Conversion)’까지 가능하게 하는 기능입니다.
- OpenAI에서 제공하고 있는 GPT 플러그인들은 ‘기능 호출’을 사용해 만들어진 것입니다 - Introduction - OpenAI API

- 챗GPT 기능 호출 사례. ChatGPT (openai.com)
- 네이버의 CUE : 스킬(Skill)이라는 명칭으로 제공됩니다 Cue: : 네이버 통합검색 (naver.com)
- Google Bard : 확장 프로그램(Extension)이라는 이름으로 제공됩니다 Introducing Extensions ✨ | Bard

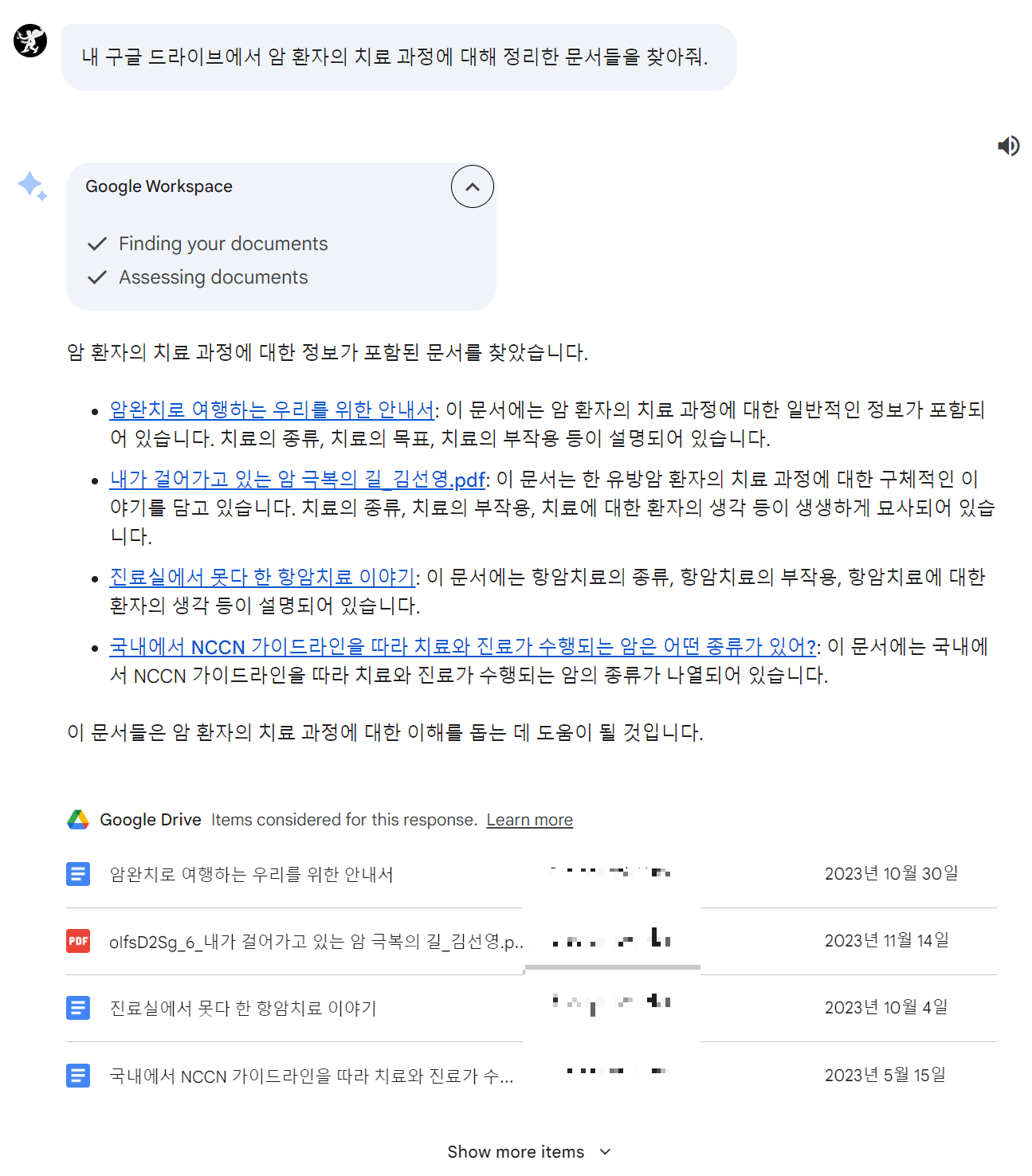
- Bard 기능 호출 사례1. 나의 구글 드라이브에서 특정 문서를 찾고 관련된 유튜브 영상을 추천

- Bard 기능 호출 사례2. 항공권을 예약하고 맛집을 추천


프롬프트 템플릿
이용자의 아무 말을 모두 커버할 수 있는 범용성과 추론 능력을 갖추고 있지 않다면, 이용자에게 프롬프트 엔지니어링의 부담을 지우고 싶지 않다면, 개방형 프롬프트가 아니라 프롬프트 템플릿을 고려해 봐야 할 것입니다.
- 프롬프트 템플릿 : “{purpose}에 좋은 식단을 짜주세요”
- 이용자 입력 : “다이어트” ← 버튼으로 제공되어도 무방
'생성AI(LLM)' 카테고리의 다른 글
| 생성형 AI(거대언어모델) 비즈니스에 활용하기: 경영자/서비스기획자/PM의 필수 상식 (0) | 2024.01.21 |
|---|---|
| 챗GPT, 미드저니 같은 생성형 AI를 활용할 때 고려해야 할 법적/윤리적 이슈 (0) | 2024.01.20 |
| 챗GPT랑 GPT가 동일한 개념인 줄 아는 당신에게: 생성형 AI의 역사와 한계 (2) | 2024.01.18 |
| 텍스트 데이터 분석(Text Analysis)의 전과정에 챗GPT를 활용(프롬프트 원문 공개) (0) | 2024.01.15 |
| 거대언어모델(LLM)과 생성형 AI에 대한 모든 개념(feat. 챗GPT가 할 수 있는 일) (0) | 2024.01.14 |



