거대언어모델(LLM)과 생성형 AI에 대한 모든 개념(feat. 챗GPT가 할 수 있는 일)
거대언어모델(LLM; Large Language Model)에 대해서 몇 차례 글을 쓸 겁니다.
이 연재 글을 통해서 누구나 자신의 업무 중 어디에다 AI를 적용할지 아이디어를 발굴할 수 있는 역량을 얻었으면 합니다.
특히 업무 현장에서 중요한 '커뮤니케이션'. AI 관련된 업무 커뮤니케이션을 할 때, 동일한 용어를 동일한 뜻으로 사용하게 되길 바랍니다.

언어모델(LLM) 기반 서비스(Application) 관련 개념
서비스를 구성하는 레이어
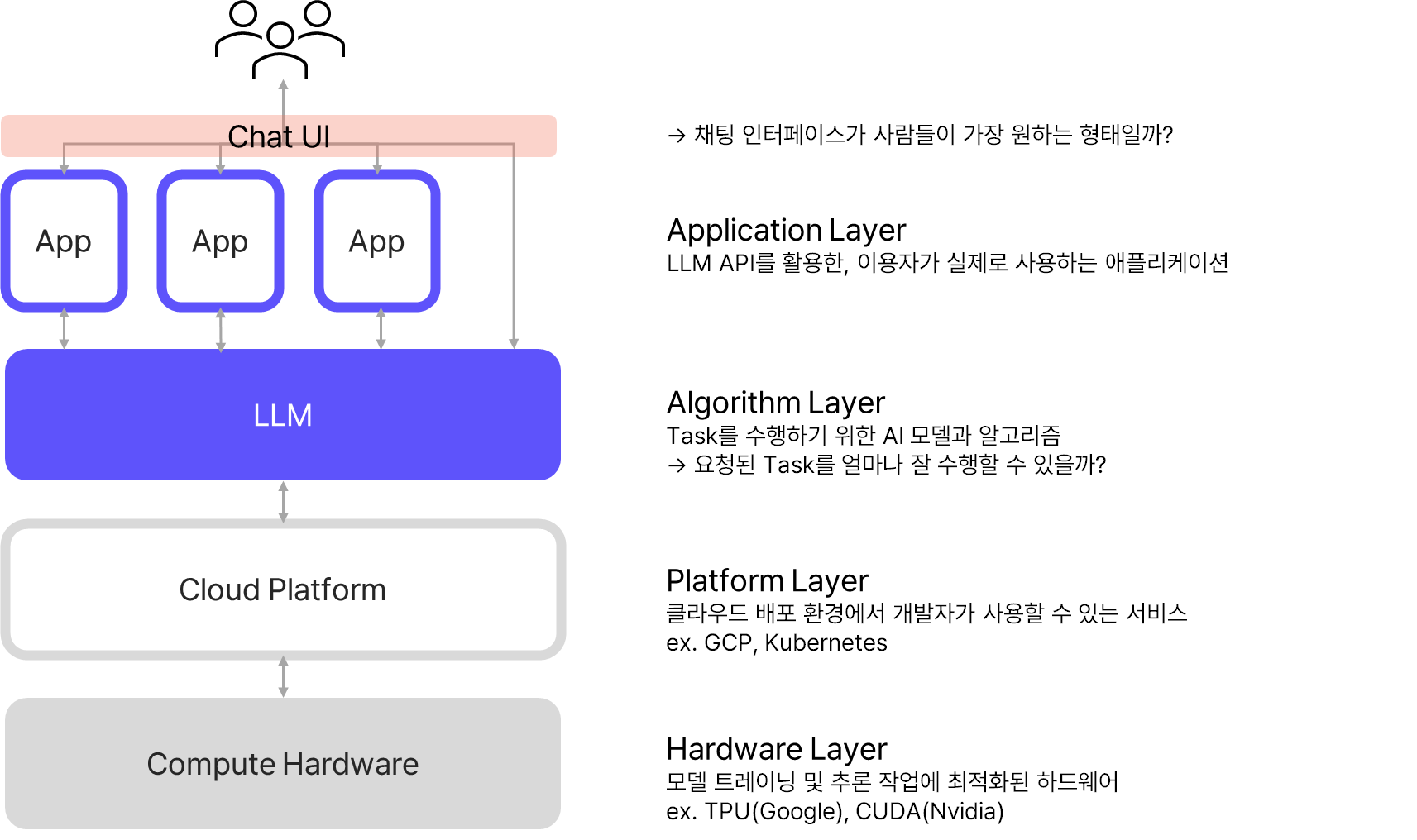
LLM = 거대 언어모델(Large Language Model)
방대한 양의 말뭉치(Corpus) 데이터를 학습하여 자연어 처리 작업을 수행하는 딥러닝 모델입니다. 임의의 문장을 입력하면 이어지는 문장을 예측하여 출력하는 방식으로 작동합니다.
- 딥러닝 : 인간의 뇌가 정보를 처리하고 배우는 방식(Neural network)을 본떠서 컴퓨터에게 많은 데이터를 주고 스스로 학습하도록 하는 기술입니다. 예를 들어, 컴퓨터에게 많은 고양이 사진을 보여주며 '이것은 고양이야'라고 알려주면, 컴퓨터는 고양이의 다양한 모습을 스스로 인식하고 학습해 나가게 됩니다. 나중에는 컴퓨터 스스로 새로운 고양이 사진을 보고 '이것도 고양이다'라고 알아볼 수 있게 되는 겁니다.
- 참고. 여러 언어모델을 직접 사용해볼 수 있는 사이트 : https://poe.com/ (하이퍼클로바X 같은 국내 모델은 없음)
GPT = Generative(생성하는) + Pre-trained(사전학습된) + Transformer(변환기)
GPT에서 'T'가 의미하는 Transformer는 딥러닝 모델의 일종입니다. Google brain이 발표한 논문에서 그 기원을 찾을 수 있습니다.(논문 : Attention is All you Need (neurips.cc))
- 즉, GPT는 Transfomer라는 모델을 사전학습시켜 콘텐츠를 생성하도록 만든 딥러닝 언어모델입니다.
- OpenAI의 대표적인 언어모델이 GPT이지만, 아래 <표>처럼 GPT 외에도 OpenAI는 다양한 모델을 보유하고 있습니다 :
| 모드(Mode) | 해당 모델(Model) | 설명 | 공식 문서 링크 |
| 채팅(Chat) | gpt-3.5-turbo | 채팅 메시지 리스트를 입력으로 받아서 응답(텍스트)을 생성하는 모드. 텍스트 생성 모드보다 이용 요금이 저렴 - 채팅 메시지에는 role과 콘텐츠가 포함되는데, role은 system(채팅AI의 행동에 대한 지시), user(이용자의 발화), assistant(AI의 발화) 세 가지. system에 입력한 지시문에 맞추어 AI의 답변을 일관성을 유지 |
|
| Complete(텍스트 생성) | - gpt-3.5-turbo - davinci-002 - babbage-002 (Fine-tuning model) |
임의의 텍스트를 입력으로 받아서 뒤에 오는 텍스트를 생성하는 모드 - 텍스트 생성 : 주어진 키워드나 조건에 맞게 문장을 자동으로 생성하는 작업 - 질의응답 : 주어진 질문에 대한 답변을 생성 - 요약 : 주어진 글을 짧고 간결하게 정리하는 작업 - 번역 : 특정 언어로 작성된 텍스트를 다른 언어로 변환하는 작업 - 프로그램 생성 : 프로그래밍 언어의 코드를 생성하는 작업 |
https://platform.openai.com/docs/guides/text-generation |
| Embedding(임베딩) | ada v2 | 텍스트를 입력받아 벡터(부동소수점 배열)로 변환. 유사한 의미를 가진 단어나 문장은 벡터 거리가 가깝고, 유사하지 않은 의미를 가진 단어나 문장은 벡터 거리가 멀어지도록 설계된 구조 - 검색 : 쿼리 문자열과의 연관성에 따라 결과의 순위를 매김 - 클러스터링 : 텍스트의 연관성을 기준으로 그루핑 - 추천 : 텍스트의 연관성을 기준으로 추천 - 이상치 탐지 : 유사도가 거의 없는 이상치 탐지 - 다양성 측정 : 유사도 분포 분석 - 분류 : 텍스트가 가장 유사한 라벨에 따라 분류 |
https://platform.openai.com/docs/guides/embeddings |
| 이미지 생성 | DALL·E 3 | - 텍스트에서 이미지 생성 - 이미지 편집 - 이미지에서 변형된 이미지 생성(Out-painting 등) |
https://platform.openai.com/docs/guides/images?context=node |
| 음성 텍스트 변환 | Whisper | - 음성을 텍스트로 변환(STT) ※ TTS는 Whisper가 아닌 별도의 TTS 모델 존재 - 음성을 영어로 번역하여 텍스트로 변환 |
https://platform.openai.com/docs/guides/speech-to-text |
위에 기재된 모드(Mode) 외에도 거대 언어모델(LLM)은 다양한 과업을 수행할 수 있습니다.
아래는 <Super-naturalinstructions Generalization via declarative instructions on 1600+ nlp tasks>라는 논문에서 정리한 "LLM이 수행할 수 있는 과업(task)"의 목록입니다.

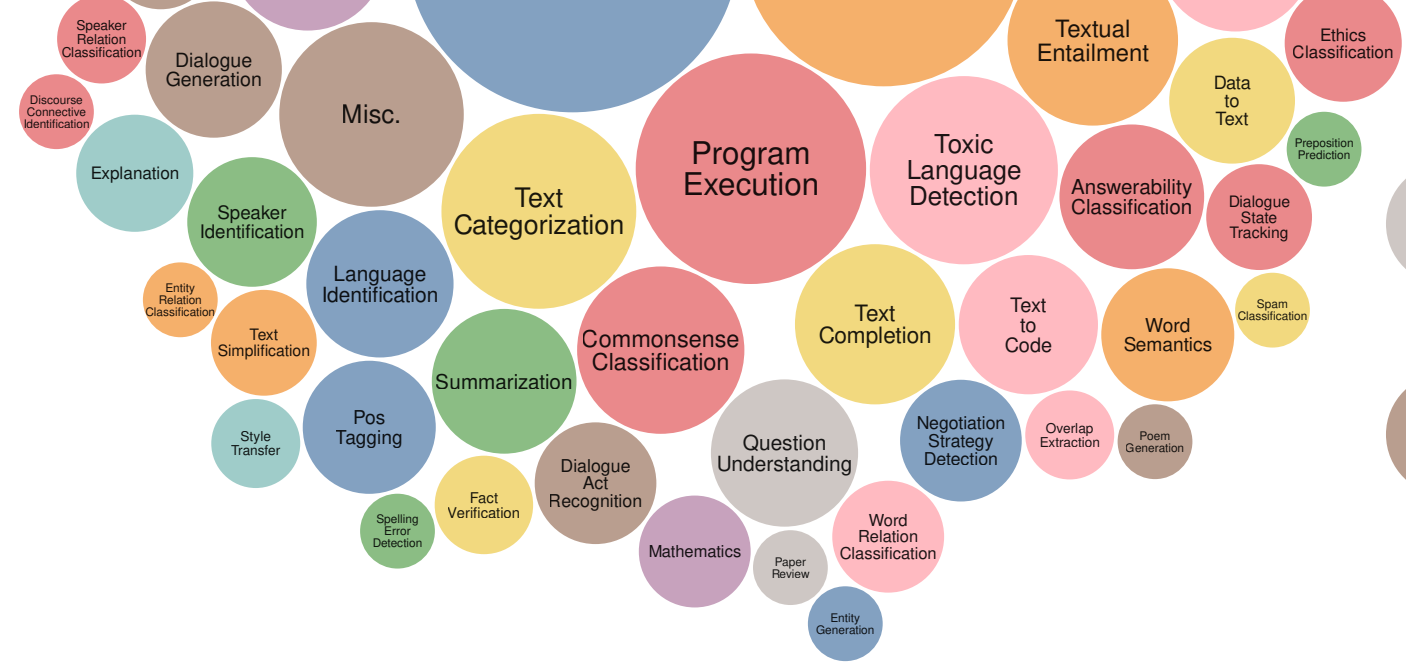
저는 또 이 그림 파일을 챗GPT에게 넘겨서 이미지 안에 등장하는 텍스트를 모두 추출(OCR)해 달라고 부탁했습니다. 아래와 같이 깔끔하게 추출해 주더군요. 이게 LLM의 힘입니다.
- Translation : 번역
- Question Answering : 질문 응답
- Program Execution : 프로그램 실행
- Question Generation : 질문 생성
- Sentiment Analysis : 감정 분석
- Text Categorization : 텍스트 분류
- Text Matching : 텍스트 매칭
- Toxic Language Detection : 유해 언어 탐지
- Information Extraction : 정보 추출
- Cause Effect Classification : 인과 관계 분류
- Textual Entailment : 텍스트 함축
- Named Entity Recognition : 지정된 개체 인식
- Fill in The Blank : 빈칸 채우기
- Wrong Candidate Generation : 잘못된 후보 생성
- Sentence Composition : 문장 구성
- Sentence Perturbation : 문장 변형
- Paraphrasing : 재구성
- Commonsense Classification : 상식 분류
- Language Identification : 언어 식별
- Answerability Classification : 답변 가능 여부 분류
- Text Completion : 텍스트 완성
- Summarization : 요약
- Word Semantics : 단어 의미론
- Text to Code : 텍스트를 코드로
- Question Rewriting : 질문 재작성
- Question Understanding : 질문 이해
- Text Quality Evaluation : 텍스트 품질 평가
- Linguistic Probing : 언어 탐색
- Story Composition : 스토리 구성
- Coherence Classification : 일관성 분류
- Word Analogy : 단어 유추
- Keyword Tagging : 키워드 태깅
- Data to Text : 데이터를 텍스트로
- Dialogue Generation : 대화 생성
- Explanation : 설명
- Speaker Identification : 화자 식별
- POS Tagging : 품사 태깅
- Dialogue Act Recognition : 대화 행위 인식
- Negotiation Strategy Detection : 협상 전략 탐지
- Word Relation Classification : 단어 관계 분류
- Number Conversion : 숫자 변환
- Grammar Error Correction : 문법 오류 수정
- Coreference Resolution : 동일 출처 분석
- Section Classification : 섹션 분류
- Answer Verification : 답변 검증
- Title Generation : 제목 생성
- Gender Classification : 성별 분류
- Sentence Compression : 문장 압축
- Punctuation Error Detection : 구두점 오류 탐지
- Stance Detection : 입장 탐지
- Stereotype Detection : 스테레오타입 탐지
- Intent Identification : 의도 식별
- Code to Text : 코드를 텍스트로
- Sentence Expansion : 문장 확장
- Grammar Error Detection : 문법 오류 탐지
- Question Decomposition : 질문 분해
- Discourse Relation Classification : 담화 관계 분류
- Irony Detection : 아이러니 탐지
- Sentence Ordering : 문장 정렬
- Speaker Relation Classification : 화자 관계 분류
- Discourse Connective Identification : 담화 연결어 식별
- Entity Relation Classification : 개체 관계 분류
- Text Simplification : 텍스트 단순화
- Style Transfer : 스타일 변환
- Fact Verification : 사실 검증
- Overlap Extraction : 중복 추출
- Poem Generation : 시 생성
- Spelling Error Detection : 철자 오류 탐지
- Mathematics : 수학
- Paper Review : 논문 리뷰
- Entity Generation : 개체 생성
- Ethics Classification : 윤리 분류
- Preposition Prediction : 전치사 예측
- Dialogue State Tracking : 대화 상태 추적
- Spam Classification : 스팸 분류
- Misc. : 기타
챗GPT=Chat + GPT
'챗GPT'는 GPT라는 언어모델을 기반으로 사람과 자연스럽게 대화(Chat)할 수 있게 개발된 서비스(Application)입니다. 즉, ‘챗GPT’와 ‘GPT’는 완전히 다른 차원의 개념입니다.
처음에 보여드린 이미지에서 Application Layer에 속하는 부분입니다. 최고 수준의 언어모델(a.k.a. SOTA LLM; State of the Art LLM)은 마치 사람과 대화하는 것처럼 자연스러운 대화가 가능하기 때문에, 이런 SOTA LLM을 내놓은 빅테크 기업들은 자사 모델을 기반으로 채팅 로봇을 서비스하고 있습니다.
오픈AI의 챗GPT : GPT 이 관계는 다른 빅테크의 거대 언어모델 챗봇에서도 발견됩니다 :
- 네이버 CUE : 하이퍼클로바X
- 구글의 Bard : PaLM(Pathways Language Model)2 (← LaMDA(Language Model for Dialogue Application))
- 참고. 생성형AI 챗봇 서비스(Application)와 기반 언어모델(LLM)
| 개발사 | 언어모델 분류 | 제공 채널 | 차별점 | |
| 챗GPT | 오픈AI | 자체 개발한 GPT 시리즈 | 웹+앱 | · 각종 플러그인 · 챗봇 빌더(GPTs) · 스토어 · 고급 데이터 분석 · 커스텀 인스트럭션 · Bing 검색엔진 연동 · 멀티 모달 |
| Bing Copilot | 마이크로소프트 | GPT-4 + Bing검색 | 웹+앱 | · Bing 검색엔진 연동 · 출처 표시 · 답변 스타일 선택 · 멀티 모달 |
| Bard | 구글 | 자체 개발한 PaLM2 | 웹 | · 구글 서비스 연동(Extension) · 구글 검색엔진 연동 |
| 클로바X | 네이버 | 자체 개발한 하이퍼클로바X | 웹 | · 네이버 서비스 연동(Skill) · 네이버 검색엔진 연동 |
| Wrtn(뤼튼) | 뤼튼테크놀로지 | API 기반(GPT+하이퍼클로바X+PaLM) | 웹+앱 | · 뤼튼 스토어(도구)를 통한 챗봇 생태계 구축 |
| 아숙업 | 업스테이지 | APT 기반(GPT) | 카카오톡 | · OCR(광학문자인식) 특화 기능 · 카카오톡 기반으로 높은 접근성 |
| 웍스(Works AI) | 체인파트너스 | API 기반(GPT+DeepL) | 웹+앱 | · 버튼형 자동화(작업 요청 위해 프롬프트 작성할 필요 없음) · 직장인 업무 수행 맥락에 특화 |
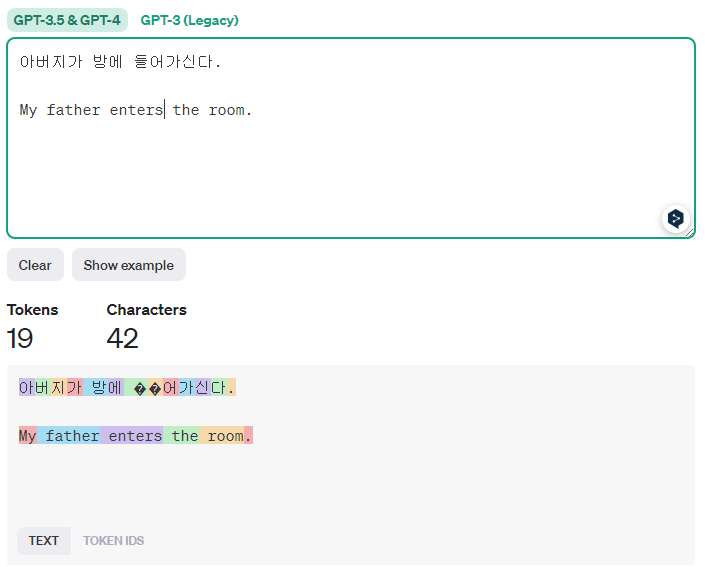
토큰(Token)
언어모델이 데이터를 처리하는 과정에서 잘게 쪼갠 텍스트의 단위(Not 단어, Not 음절)입니다. OpenAI API 이용료 과금의 기준이기도 합니다.
영어와 한국어를 토큰으로 나누면(Tokenize),
- 영어의 경우 띄어쓰기를 기준으로 의미를 분절. 단어 1개를 처리하는 데 1~2개의 토큰 사용합니다.
- 한국어는 조사와 어미에 따라 단어의 의미가 달라지기 때문에 띄어쓰기 기준으로 의미를 분절할 수 없고 음절 단위로 토큰을 나눕니다. 음절마다 1개 토큰을 사용하기 때문에, API를 한국어로 사용할 때 영어보다 2.5~5배 비싸진다고 알려져 있습니다.
- 참고. 오픈AI 토크나이저(+시각화) : https://platform.openai.com/tokenizer
자, 여기까지는 거대언어모델(LLM)과 관련된 기본 중의 기본 개념입니다. 다음 포스팅에서는 거대언어모델, 특히 챗GPT와 관련된 심화된 개념들이 나올 겁니다.
챗GPT 프롬프트 엔지니어링 꿀팁과 파인튜닝 관련 필수 개념 (tistory.com)
챗GPT 프롬프트 엔지니어링 꿀팁과 파인튜닝 관련 필수 개념
첫 번째 글에서는 거대언어모델(LLM; Lager Language Model)로 서비스(애플리케이션)를 구현하고자 할 때 알아야 할 필수적인 개념을 정리했습니다. 아래 링크에서 기본 개념 확인할 수 있어요. 거대언
mokeya2.tistory.com
모두 거대언어모델(생성형 AI)을 우리 서비스, 내 목적에 맞게 활용하기 위해 알아야 하는 개념입니다. 개념을 소개하는 중간중간, "프롬프트 엔지니어링" 기법과 그 유명한 "파인튜닝" 연관 개념들도 알려 드리겠습니다.